 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2MF-Net: A Recurrent Residual Multi-Path Fusion Network for Robust Multi-directional Spine X-ray Segmentation
Dec 08, 2025



Accurate segmentation of spinal structures in X-ray images is a prerequisite for quantitative scoliosis assessment, including Cobb angle measurement, vertebral translation estimation and curvature classification. In routine practice, clinicians acquire coronal, left-bending and right-bending radiographs to jointly evaluate deformity severity and spinal flexibility. However, the segmentation step remains heavily manual, time-consuming and non-reproducible, particularly in low-contrast images and in the presence of rib shadows or overlapping tissues. To address these limitations, this paper proposes R2MF-Net, a recurrent residual multi-path encoder--decoder network tailored for automatic segmentation of multi-directional spine X-ray images. The overall design consists of a coarse segmentation network and a fine segmentation network connected in cascade. Both stages adopt an improved Inception-style multi-branch feature extractor, while a recurrent residual jump connection (R2-Jump) module is inserted into skip paths to gradually align encoder and decoder semantics. A multi-scale cross-stage skip (MC-Skip) mechanism allows the fine network to reuse hierarchical representations from multiple decoder levels of the coarse network, thereby strengthening the stability of segmentation across imaging directions and contrast conditions. Furthermore, a lightweight spatial-channel squeeze-and-excitation block (SCSE-Lite) is employed at the bottleneck to emphasize spine-related activations and suppress irrelevant structures and background noise. We evaluate R2MF-Net on a clinical multi-view radiograph dataset comprising 228 sets of coronal, left-bending and right-bending spine X-ray images with expert annotations.
Precise Liver Tumor Segmentation in CT Using a Hybrid Deep Learning-Radiomics Framework
Dec 08, 2025Accurate three-dimensional delineation of liver tumors on contrast-enhanced CT is a prerequisite for treatment planning, navigation and response assessment, yet manual contouring is slow, observer-dependent and difficult to standardise across centres. Automatic segmentation is complicated by low lesion-parenchyma contrast, blurred or incomplete boundaries, heterogeneous enhancement patterns, and confounding structures such as vessels and adjacent organs. We propose a hybrid framework that couples an attention-enhanced cascaded U-Net with handcrafted radiomics and voxel-wise 3D CNN refinement for joint liver and liver-tumor segmentation. First, a 2.5D two-stage network with a densely connected encoder, sub-pixel convolution decoders and multi-scale attention gates produces initial liver and tumor probability maps from short stacks of axial slices. Inter-slice temporal consistency is then enforced by a simple three-slice refinement rule along the cranio-caudal direction, which restores thin and tiny lesions while suppressing isolated noise. Next, 728 radiomic descriptors spanning intensity, texture, shape, boundary and wavelet feature groups are extracted from candidate lesions and reduced to 20 stable, highly informative features via multi-strategy feature selection; a random forest classifier uses these features to reject false-positive regions. Finally, a compact 3D patch-based CNN derived from AlexNet operates in a narrow band around the tumor boundary to perform voxel-level relabelling and contour smoothing.
Dual-Stream Cross-Modal Representation Learning via Residual Semantic Decorrelation
Dec 08, 2025



Cross-modal learning has become a fundamental paradigm for integrating heterogeneous information sources such as images, text, and structured attributes. However, multimodal representations often suffer from modality dominance, redundant information coupling, and spurious cross-modal correlations, leading to suboptimal generalization and limited interpretability. In particular, high-variance modalities tend to overshadow weaker but semantically important signals, while naïve fusion strategies entangle modality-shared and modality-specific factors in an uncontrolled manner. This makes it difficult to understand which modality actually drives a prediction and to maintain robustness when some modalities are noisy or missing. To address these challenges, we propose a Dual-Stream Residual Semantic Decorrelation Network (DSRSD-Net), a simple yet effective framework that disentangles modality-specific and modality-shared information through residual decomposition and explicit semantic decorrelation constraints. DSRSD-Net introduces: (1) a dual-stream representation learning module that separates intra-modal (private) and inter-modal (shared) latent factors via residual projection; (2) a residual semantic alignment head that maps shared factors from different modalities into a common space using a combination of contrastive and regression-style objectives; and (3) a decorrelation and orthogonality loss that regularizes the covariance structure of the shared space while enforcing orthogonality between shared and private streams, thereby suppressing cross-modal redundancy and preventing feature collapse. Experimental results on two large-scale educational benchmarks demonstrate that DSRSD-Net consistently improves next-step prediction and final outcome prediction over strong single-modality, early-fusion, late-fusion, and co-attention baselines.
Deep Learning for Logo Detection: A Survey
Oct 10, 2022
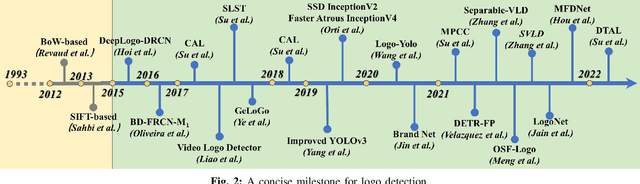

When logos are increasingly created, logo detection has gradually become a research hotspot across many domains and tasks. Recent advances in this area are dominated by deep learning-based solutions, where many datasets, learning strategies, network architectures, etc. have been employed. This paper reviews the advance in applying deep learning techniques to logo detection. Firstly, we discuss a comprehensive account of public datasets designed to facilitate performance evaluation of logo detection algorithms, which tend to be more diverse, more challenging, and more reflective of real life. Next, we perform an in-depth analysis of the existing logo detection strategies and the strengths and weaknesses of each learning strategy. Subsequently, we summarize the applications of logo detection in various fields, from intelligent transportation and brand monitoring to copyright and trademark compliance. Finally, we analyze the potential challenges and present the future directions for the development of logo detection to complete this survey.
Discriminative Semantic Feature Pyramid Network with Guided Anchoring for Logo Detection
Aug 31, 2021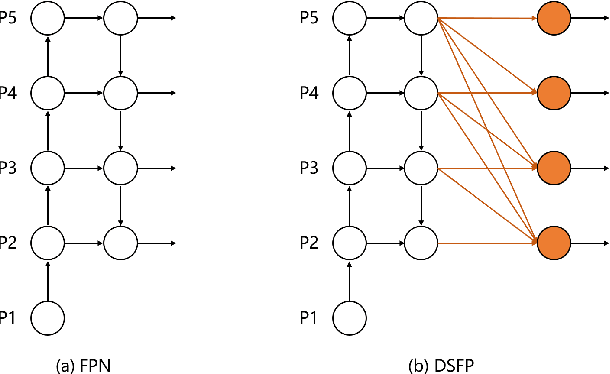
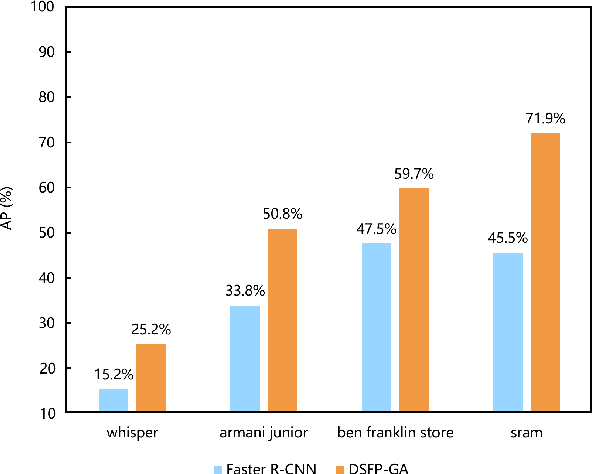
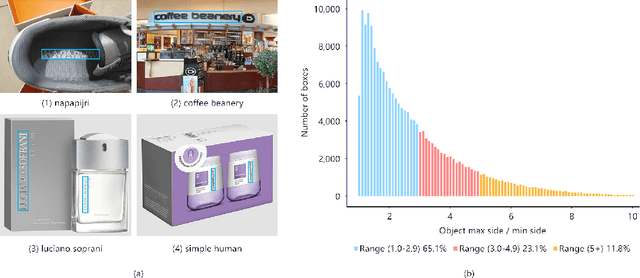
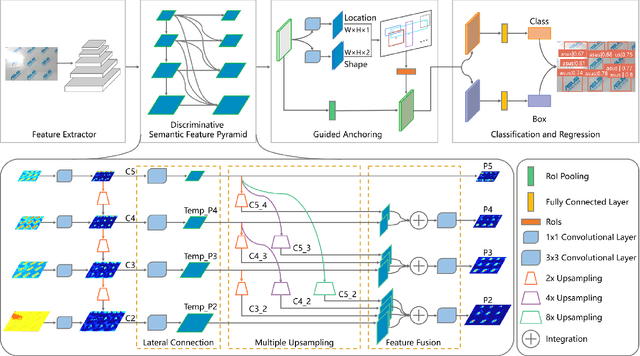
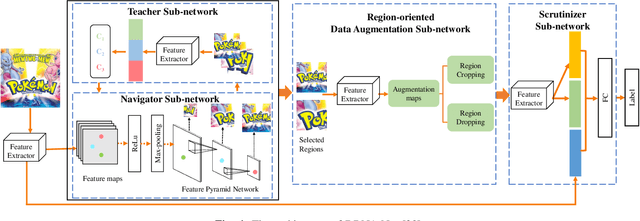
Recently, logo detection has received more and more attention for its wide applications in the multimedia field, such as intellectual property protection, product brand management, and logo duration monitoring. Unlike general object detection, logo detection is a challenging task, especially for small logo objects and large aspect ratio logo objects in the real-world scenario. In this paper, we propose a novel approach, named Discriminative Semantic Feature Pyramid Network with Guided Anchoring (DSFP-GA), which can address these challenges via aggregating the semantic information and generating different aspect ratio anchor boxes. More specifically, our approach mainly consists of Discriminative Semantic Feature Pyramid (DSFP) and Guided Anchoring (GA). Considering that low-level feature maps that are used to detect small logo objects lack semantic information, we propose the DSFP, which can enrich more discriminative semantic features of low-level feature maps and can achieve better performance on small logo objects. Furthermore, preset anchor boxes are less efficient for detecting large aspect ratio logo objects. We therefore integrate the GA into our method to generate large aspect ratio anchor boxes to mitigate this issue. Extensive experimental results on four benchmarks demonstrate the effectiveness of our proposed DSFP-GA. Moreover, we further conduct visual analysis and ablation studies to illustrate the advantage of our method in detecting small and large aspect logo objects. The code and models can be found at https://github.com/Zhangbaisong/DSFP-GA.
FoodLogoDet-1500: A Dataset for Large-Scale Food Logo Detection via Multi-Scale Feature Decoupling Network
Aug 10, 2021
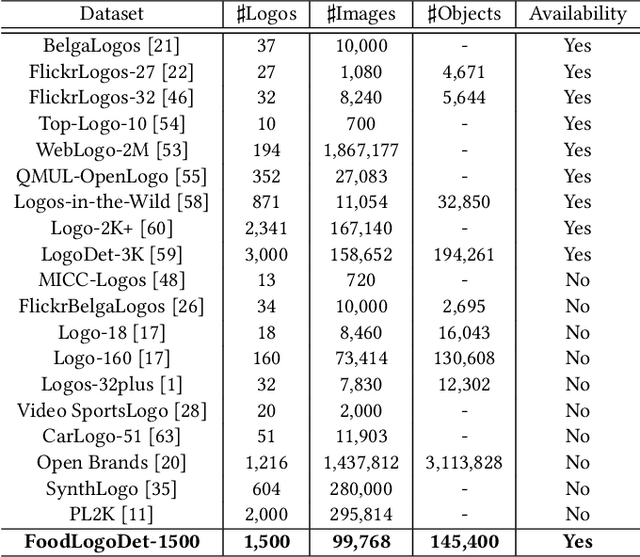
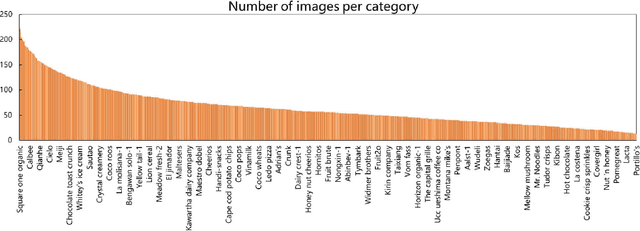
Food logo detection plays an important role in the multimedia for its wide real-world applications, such as food recommendation of the self-service shop and infringement detection on e-commerce platforms. A large-scale food logo dataset is urgently needed for developing advanced food logo detection algorithms. However, there are no available food logo datasets with food brand information. To support efforts towards food logo detection, we introduce the dataset FoodLogoDet-1500, a new large-scale publicly available food logo dataset, which has 1,500 categories, about 100,000 images and about 150,000 manually annotated food logo objects. We describe the collection and annotation process of FoodLogoDet-1500, analyze its scale and diversity, and compare it with other logo datasets. To the best of our knowledge, FoodLogoDet-1500 is the first largest publicly available high-quality dataset for food logo detection. The challenge of food logo detection lies in the large-scale categories and similarities between food logo categories. For that, we propose a novel food logo detection method Multi-scale Feature Decoupling Network (MFDNet), which decouples classification and regression into two branches and focuses on the classification branch to solve the problem of distinguishing multiple food logo categories. Specifically, we introduce the feature offset module, which utilizes the deformation-learning for optimal classification offset and can effectively obtain the most representative features of classification in detection. In addition, we adopt a balanced feature pyramid in MFDNet, which pays attention to global information, balances the multi-scale feature maps, and enhances feature extraction capability. Comprehensive experiments on FoodLogoDet-1500 and other two benchmark logo datasets demonstrate the effectiveness of the proposed method. The FoodLogoDet-1500 can be found at this https URL.
A Holistically-Guided Decoder for Deep Representation Learning with Applications to Semantic Segmentation and Object Detection
Dec 18, 2020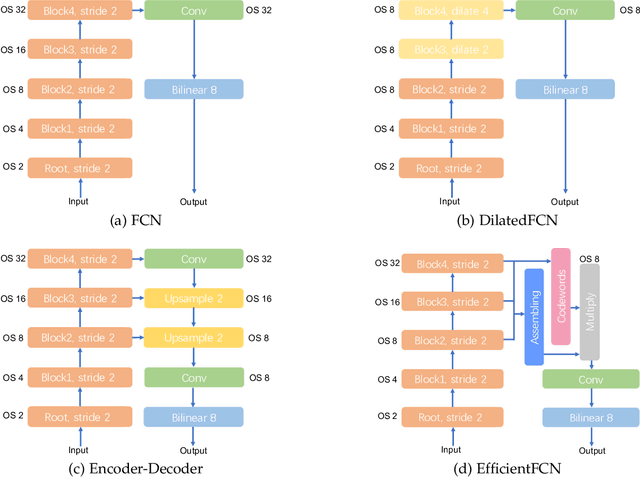
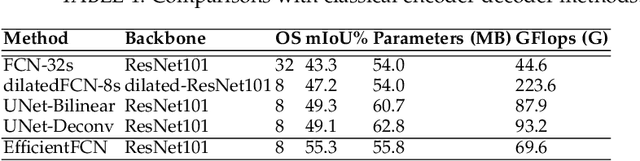
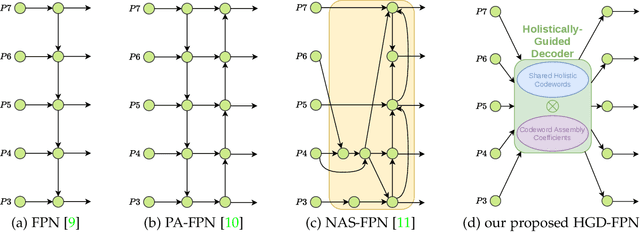
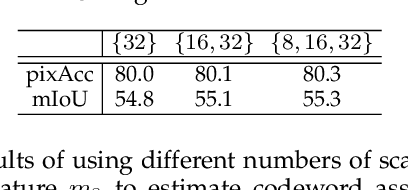
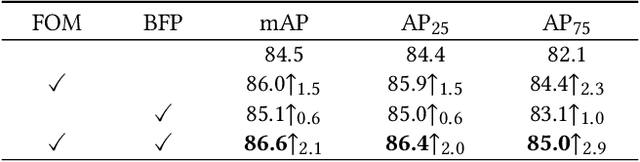
Both high-level and high-resolution feature representations are of great importance in various visual understanding tasks. To acquire high-resolution feature maps with high-level semantic information, one common strategy is to adopt dilated convolutions in the backbone networks to extract high-resolution feature maps, such as the dilatedFCN-based methods for semantic segmentation. However, due to many convolution operations are conducted on the high-resolution feature maps, such methods have large computational complexity and memory consumption. In this paper, we propose one novel holistically-guided decoder which is introduced to obtain the high-resolution semantic-rich feature maps via the multi-scale features from the encoder. The decoding is achieved via novel holistic codeword generation and codeword assembly operations, which take advantages of both the high-level and low-level features from the encoder features. With the proposed holistically-guided decoder, we implement the EfficientFCN architecture for semantic segmentation and HGD-FPN for object detection and instance segmentation. The EfficientFCN achieves comparable or even better performance than state-of-the-art methods with only 1/3 of their computational costs for semantic segmentation on PASCAL Context, PASCAL VOC, ADE20K datasets. Meanwhile, the proposed HGD-FPN achieves $>2\%$ higher mean Average Precision (mAP) when integrated into several object detection frameworks with ResNet-50 encoding backbones.
Multi-organ Segmentation via Co-training Weight-averaged Models from Few-organ Datasets
Aug 17, 2020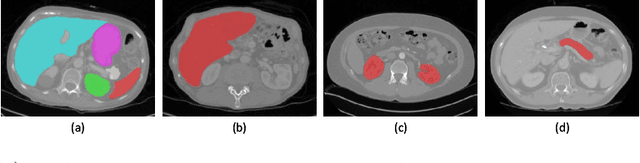
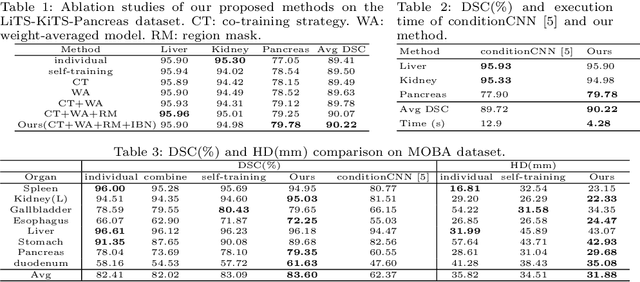
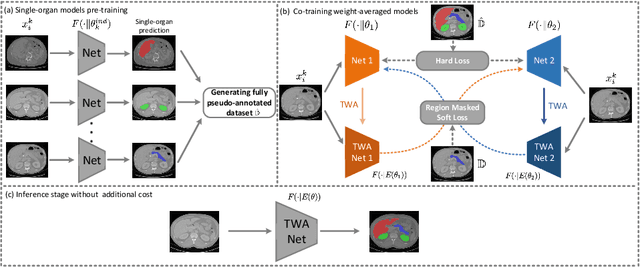
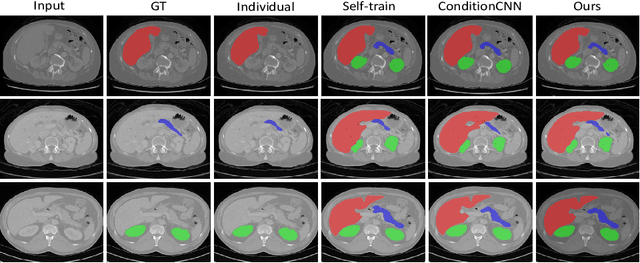
Multi-organ segmentation has extensive applications in many clinical applications. To segment multiple organs of interest, it is generally quite difficult to collect full annotations of all the organs on the same images, as some medical centers might only annotate a portion of the organs due to their own clinical practice. In most scenarios, one might obtain annotations of a single or a few organs from one training set, and obtain annotations of the the other organs from another set of training images. Existing approaches mostly train and deploy a single model for each subset of organs, which are memory intensive and also time inefficient. In this paper, we propose to co-train weight-averaged models for learning a unified multi-organ segmentation network from few-organ datasets. We collaboratively train two networks and let the coupled networks teach each other on un-annotated organs. To alleviate the noisy teaching supervisions between the networks, the weighted-averaged models are adopted to produce more reliable soft labels. In addition, a novel region mask is utilized to selectively apply the consistent constraint on the un-annotated organ regions that require collaborative teaching, which further boosts the performance. Extensive experiments on three public available single-organ datasets LiTS, KiTS, Pancreas and manually-constructed single-organ datasets from MOBA show that our method can better utilize the few-organ datasets and achieves superior performance with less inference computational cost.
LogoDet-3K: A Large-Scale Image Dataset for Logo Detection
Aug 12, 2020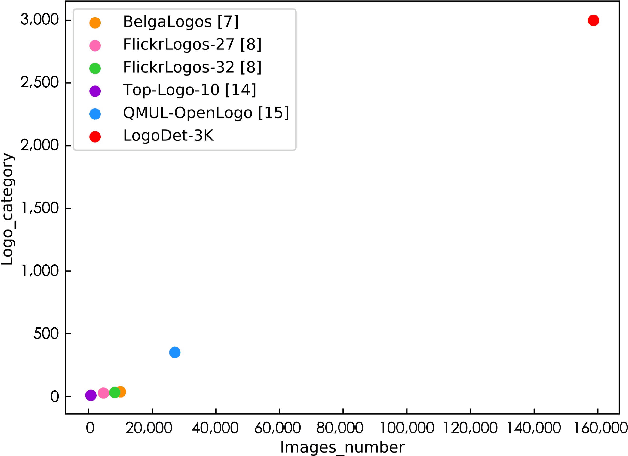
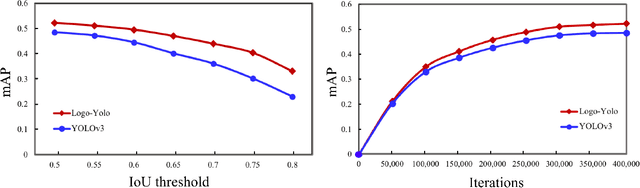


Logo detection has been gaining considerable attention because of its wide range of applications in the multimedia field, such as copyright infringement detection, brand visibility monitoring, and product brand management on social media. In this paper, we introduce LogoDet-3K, the largest logo detection dataset with full annotation, which has 3,000 logo categories, about 200,000 manually annotated logo objects and 158,652 images. LogoDet-3K creates a more challenging benchmark for logo detection, for its higher comprehensive coverage and wider variety in both logo categories and annotated objects compared with existing datasets. We describe the collection and annotation process of our dataset, analyze its scale and diversity in comparison to other datasets for logo detection. We further propose a strong baseline method Logo-Yolo, which incorporates Focal loss and CIoU loss into the state-of-the-art YOLOv3 framework for large-scale logo detection. Logo-Yolo can solve the problems of multi-scale objects, logo sample imbalance and inconsistent bounding-box regression. It obtains about 4% improvement on the average performance compared with YOLOv3, and greater improvements compared with reported several deep detection models on LogoDet-3K. The evaluations on other three existing datasets further verify the effectiveness of our method, and demonstrate better generalization ability of LogoDet-3K on logo detection and retrieval tasks. The LogoDet-3K dataset is used to promote large-scale logo-related research and it can be found at https://github.com/Wangjing1551/LogoDet-3K-Dataset.
Robust Screening of COVID-19 from Chest X-ray via Discriminative Cost-Sensitive Learning
May 21, 2020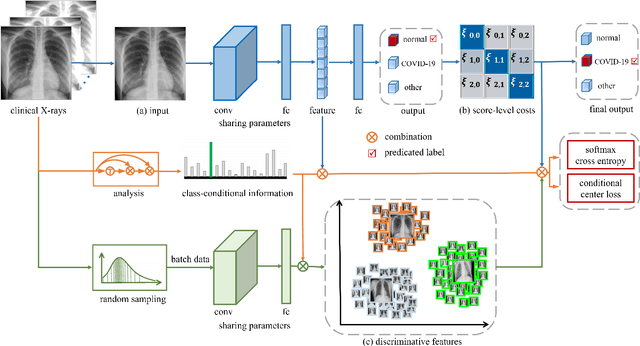
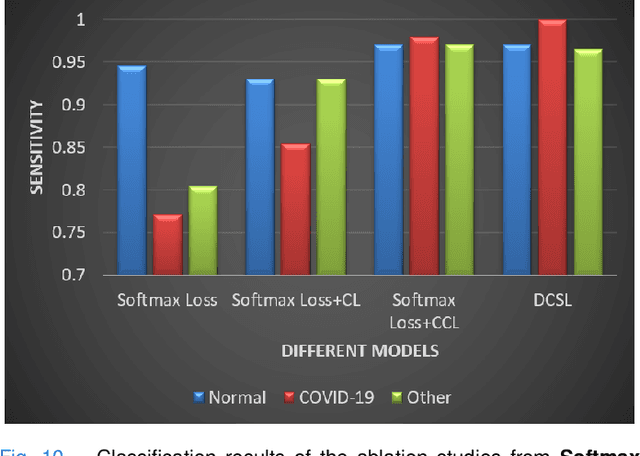
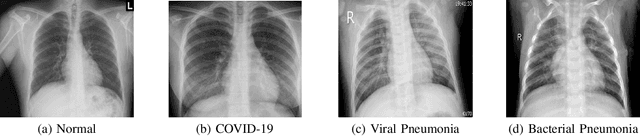
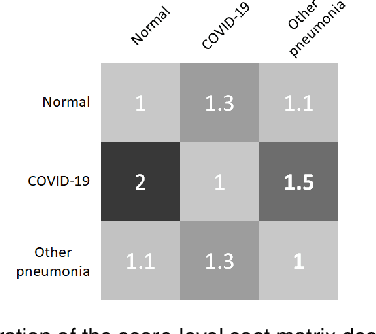
This paper addresses the new problem of automated screening of coronavirus disease 2019 (COVID-19) based on chest X-rays, which is urgently demanded toward fast stopping the pandemic. However, robust and accurate screening of COVID-19 from chest X-rays is still a globally recognized challenge because of two bottlenecks: 1) imaging features of COVID-19 share some similarities with other pneumonia on chest X-rays, and 2) the misdiagnosis rate of COVID-19 is very high, and the misdiagnosis cost is expensive. While a few pioneering works have made much progress, they underestimate both crucial bottlenecks. In this paper, we report our solution, discriminative cost-sensitive learning (DCSL), which should be the choice if the clinical needs the assisted screening of COVID-19 from chest X-rays. DCSL combines both advantages from fine-grained classification and cost-sensitive learning. Firstly, DCSL develops a conditional center loss that learns deep discriminative representation. Secondly, DCSL establishes score-level cost-sensitive learning that can adaptively enlarge the cost of misclassifying COVID-19 examples into other classes. DCSL is so flexible that it can apply in any deep neural network. We collected a large-scale multi-class dataset comprised of 2,239 chest X-ray examples: 239 examples from confirmed COVID-19 cases, 1,000 examples with confirmed bacterial or viral pneumonia cases, and 1,000 examples of healthy people. Extensive experiments on the three-class classification show that our algorithm remarkably outperforms state-of-the-art algorithms. It achieves an accuracy of 97.01%, a precision of 97%, a sensitivity of 97.09%, and an F1-score of 96.98%. These results endow our algorithm as an efficient tool for the fast large-scale screening of COVID-19.